Slice timing correction¶
The scanner collected each volume slice by slice. That means that each slice corresponds to a different time.
For example, here is a 4D FMRI image:
>>> import nibabel as nib
>>> img = nib.load('an_example_4d.nii')
>>> data = img.get_data()
You can get the 4D image from an_example_4d.nii.
This 4D FMRI image has 16 slices on the third axis (slices in z) and 100 volumes:
>>> data.shape
(64, 64, 16, 100)
The scanner acquired each of these 16 z slices at a different time, relative to the start of the TR.
For the moment, let’s consider the first volume only.
>>> vol0 = data[..., 0]
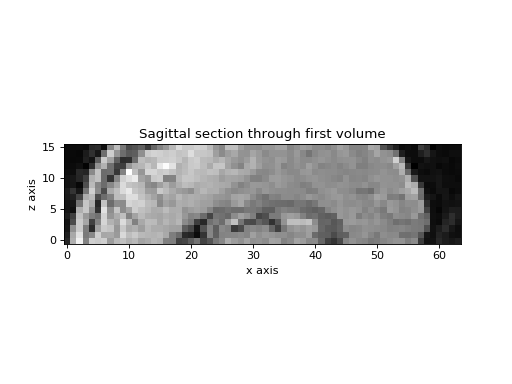
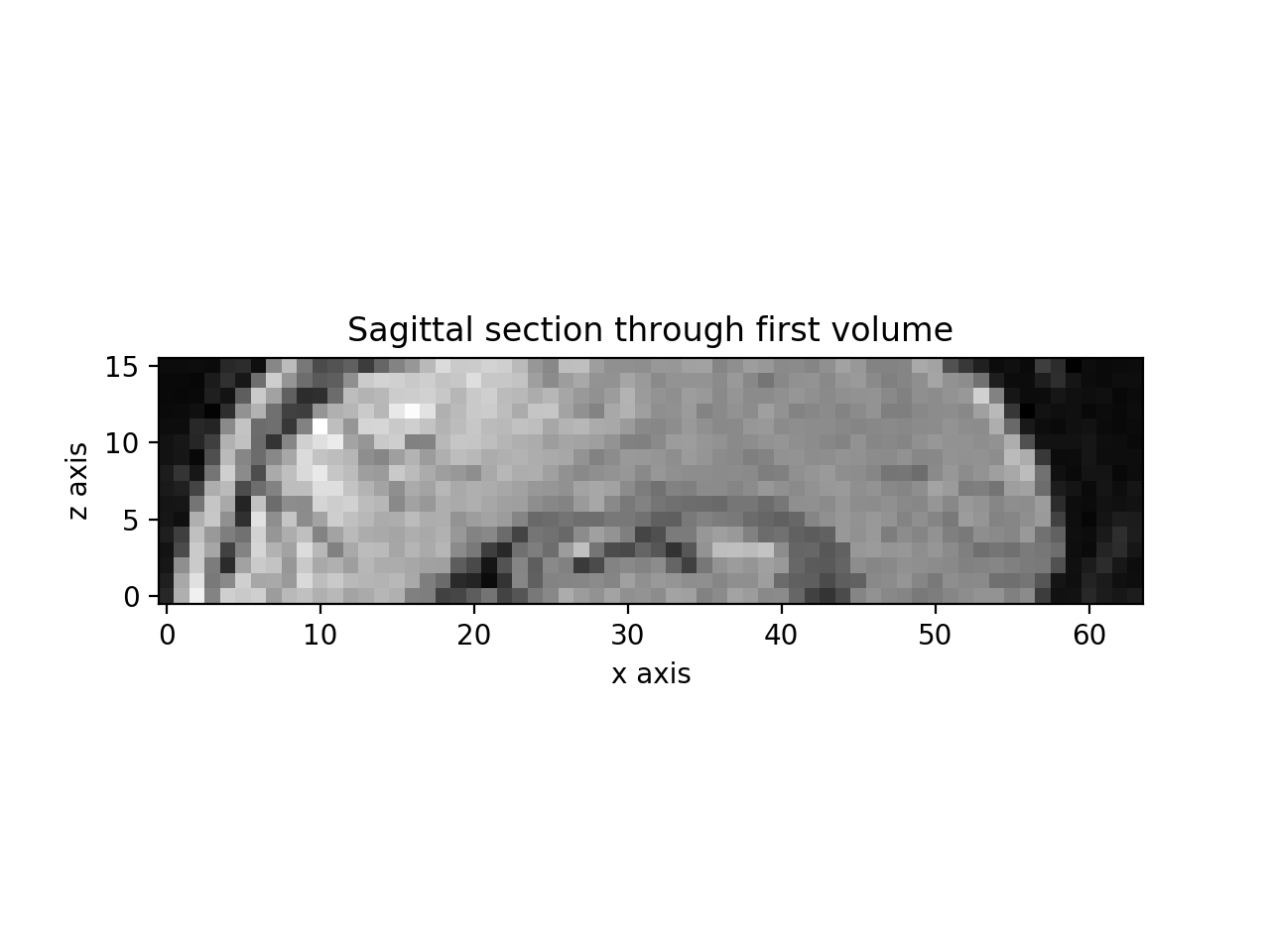
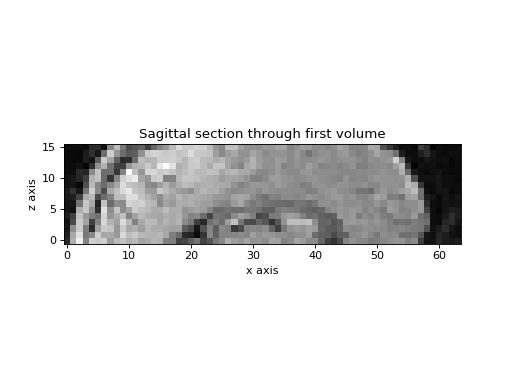
Here is a sagittal section showing the z slice positions:
Set up matplotlib
>>> import matplotlib.pyplot as plt
>>> plt.rcParams['image.cmap'] = 'gray' # default gray colormap
>>> plt.rcParams['image.interpolation'] = 'nearest'
Show sagittal section:
>>> plt.imshow(vol0[31, :, :].T, origin='bottom left')
>>> plt.title('Sagittal section through first volume')
>>> plt.xlabel('x axis')
>>> plt.ylabel('z axis')
{kind=link}
{kind=link}
The scanner acquired the slices in interleaved order, first acquiring slice index 0, 2, 4, ... 14 (where 0 is the bottom slice) then acquiring slices 1, 3, 5, .. 15:
()
So the scanner collected the bottom slice, at slice index 0, at the beginning of the TR, but it collected the next slice in space, at slice index 1, half way through the TR. Let’s say the TR == 2.0. The time that the scanner takes to acquire a single slice will be:
>>> TR = 2.0
>>> n_z_slices = 16
>>> time_for_single_slice = TR / n_z_slices
>>> time_for_single_slice
0.125
The times of acquisition of first and second slices (slice 0 and slice 1) will be:
>>> time_for_slice_0 = 0
>>> time_for_slice_1 = time_for_single_slice * 8
>>> time_for_slice_1
1.0
It may be a problem that different slices correspond to different times.
For example, later on, we may want to run some regression models on these data. We will make a predicted hemodynamic time course and regress the time series (slices over the 4th axis) against this time course. But – it would be convenient if all the voxels in one volume correspond to the same time. Otherwise we would need to sample our hemodynamic prediction at different times for different slices in the z axis.
How can we make a new 4D time series, where all the slices in each volume correspond to our best guess at what these slices would have looked like, if we had acquired them all at the same time?
This is the job of the slice timing correction.
Slice timing is interpolation in time¶
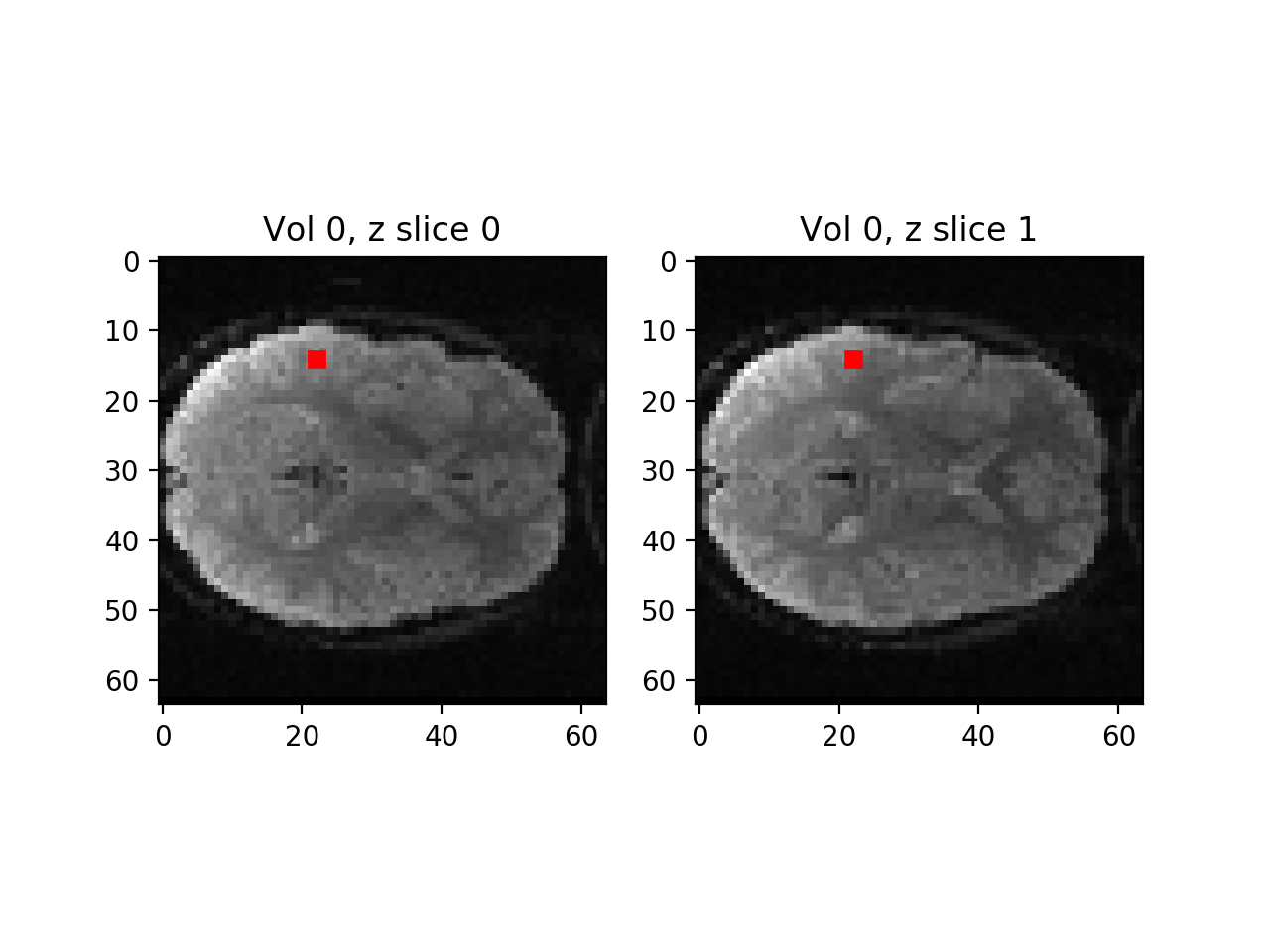
Let’s first get a time series from the bottom slice. Here’s what the bottom slice looks like, for the first volume:
>>> plt.imshow(vol0[:, :, 0])
>>> plt.title('Vol 0, z slice 0')
{kind=link}
{kind=link}

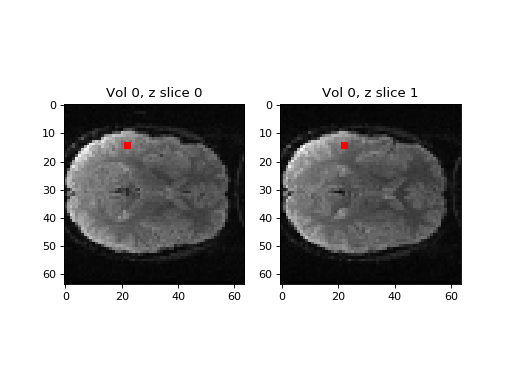
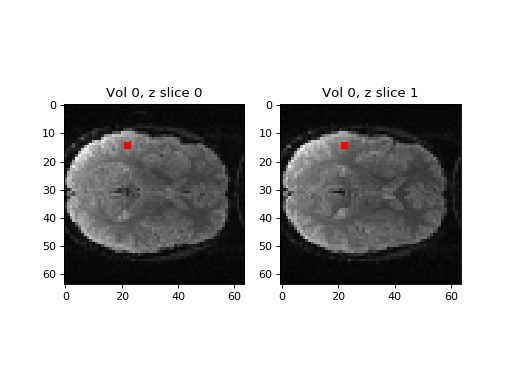
We are going to collect a time series from a sample voxel from this slice, and the slice above it (slice 1):
Our sample voxel coordinates
>>> vox_x = 14 # voxel coordinate in first dimension
>>> vox_y = 22 # voxel coordinate in second dimension
Displayed on the images:
>>> fig, axes = plt.subplots(1, 2)
>>> axes[0].imshow(vol0[:, :, 0])
>>> axes[0].set_title('Vol 0, z slice 0')
>>> axes[1].imshow(vol0[:, :, 1])
>>> axes[1].set_title('Vol 0, z slice 1')
>>> axes[0].autoscale(False)
>>> axes[0].plot(vox_y, vox_x, 'rs')
>>> axes[1].autoscale(False)
>>> axes[1].plot(vox_y, vox_x, 'rs')
{kind=link}
{kind=link}
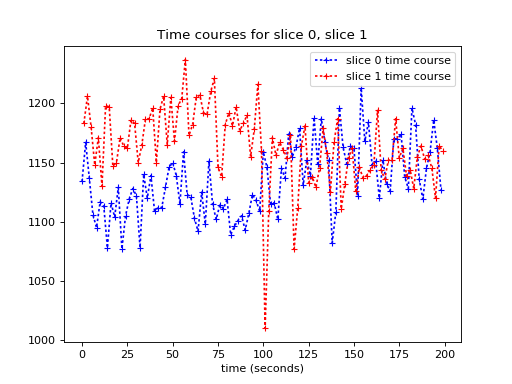
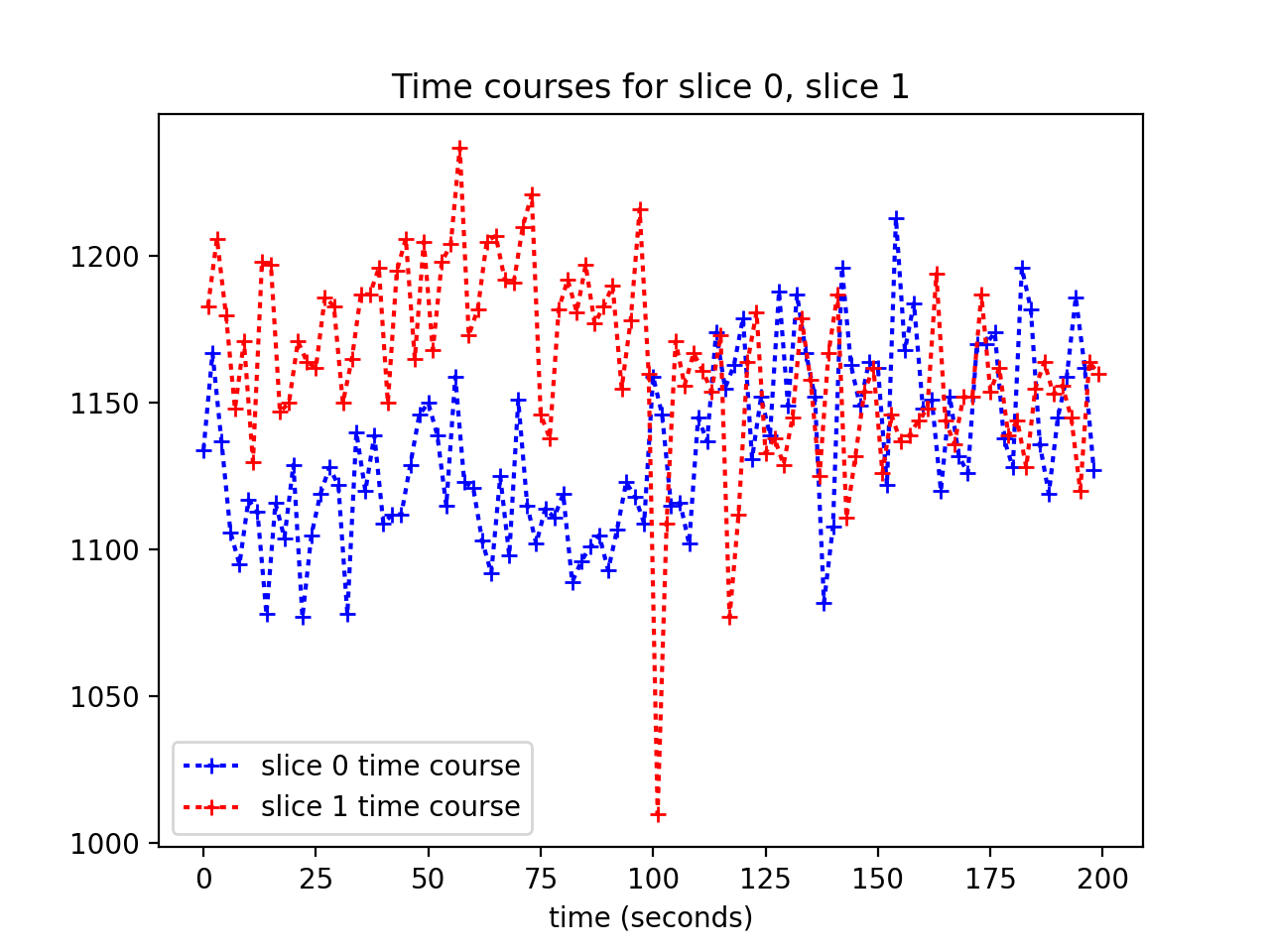
We get the time courses from slice 0 and slice 1:
>>> time_course_slice_0 = data[vox_x, vox_y, 0, :]
>>> time_course_slice_1 = data[vox_x, vox_y, 1, :]
The times of acquisition of the voxels for slice 0 are at the beginning of each TR:
>>> import numpy as np
>>> vol_nos = np.arange(data.shape[-1])
>>> vol_onset_times = vol_nos * TR
>>> times_slice_0 = vol_onset_times
The times of acquisition of the voxels in slice 1 are half a TR later:
>>> times_slice_1 = vol_onset_times + TR / 2.
We can plot the slice 0 time course against slice 0 acquisition time, along with the slice 1 time course against slice 1 acquisition time:
>>> plt.plot(times_slice_0, time_course_slice_0, 'b:+',
... label='slice 0 time course')
>>> plt.plot(times_slice_1, time_course_slice_1, 'r:+',
... label='slice 1 time course')
>>> plt.legend()
>>> plt.title('Time courses for slice 0, slice 1')
>>> plt.xlabel('time (seconds)')
{kind=link}
{kind=link}
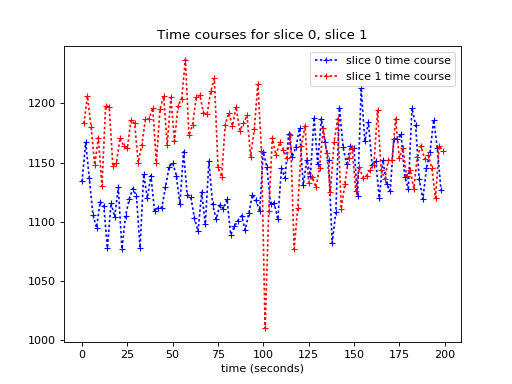
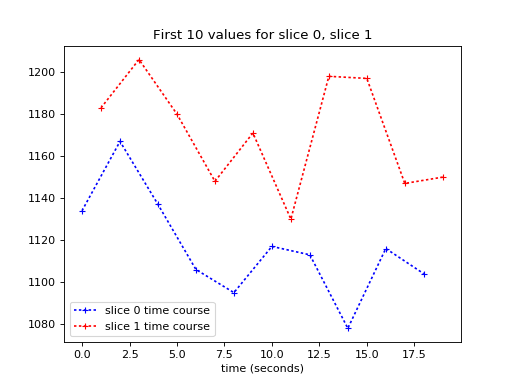
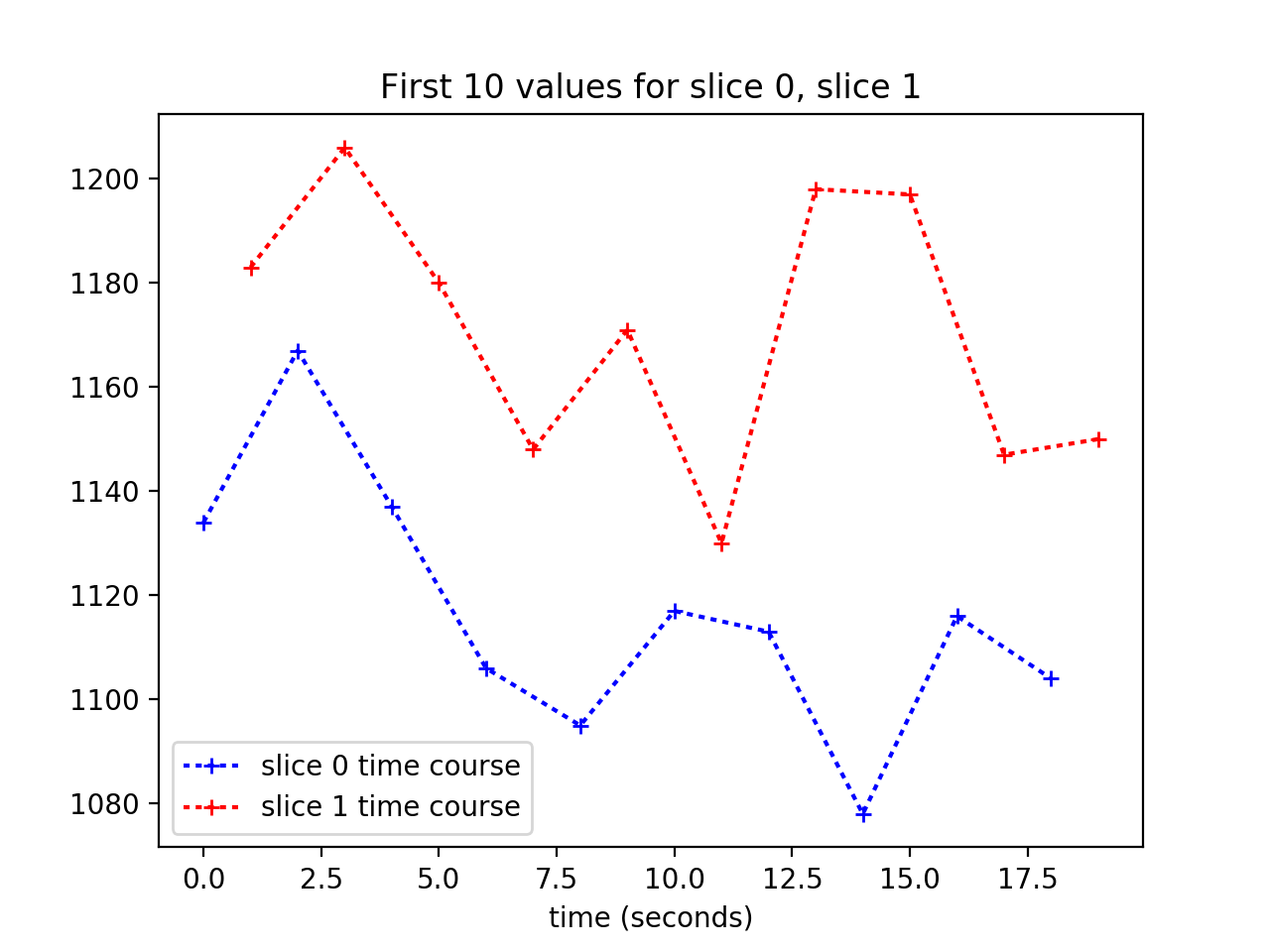
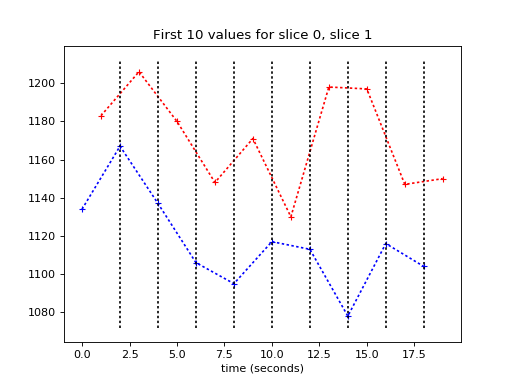
We can’t see the time offset very well here, so let’s plot only the first 10 values (values for the first 10 volumes):
>>> plt.plot(times_slice_0[:10], time_course_slice_0[:10], 'b:+',
... label='slice 0 time course')
>>> plt.plot(times_slice_1[:10], time_course_slice_1[:10], 'r:+',
... label='slice 1 time course')
>>> plt.legend()
>>> plt.title('First 10 values for slice 0, slice 1')
>>> plt.xlabel('time (seconds)')
{kind=link}
{kind=link}
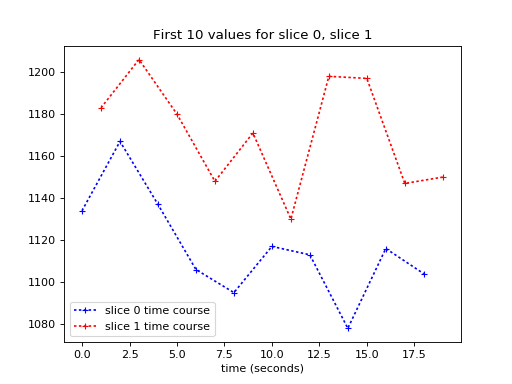
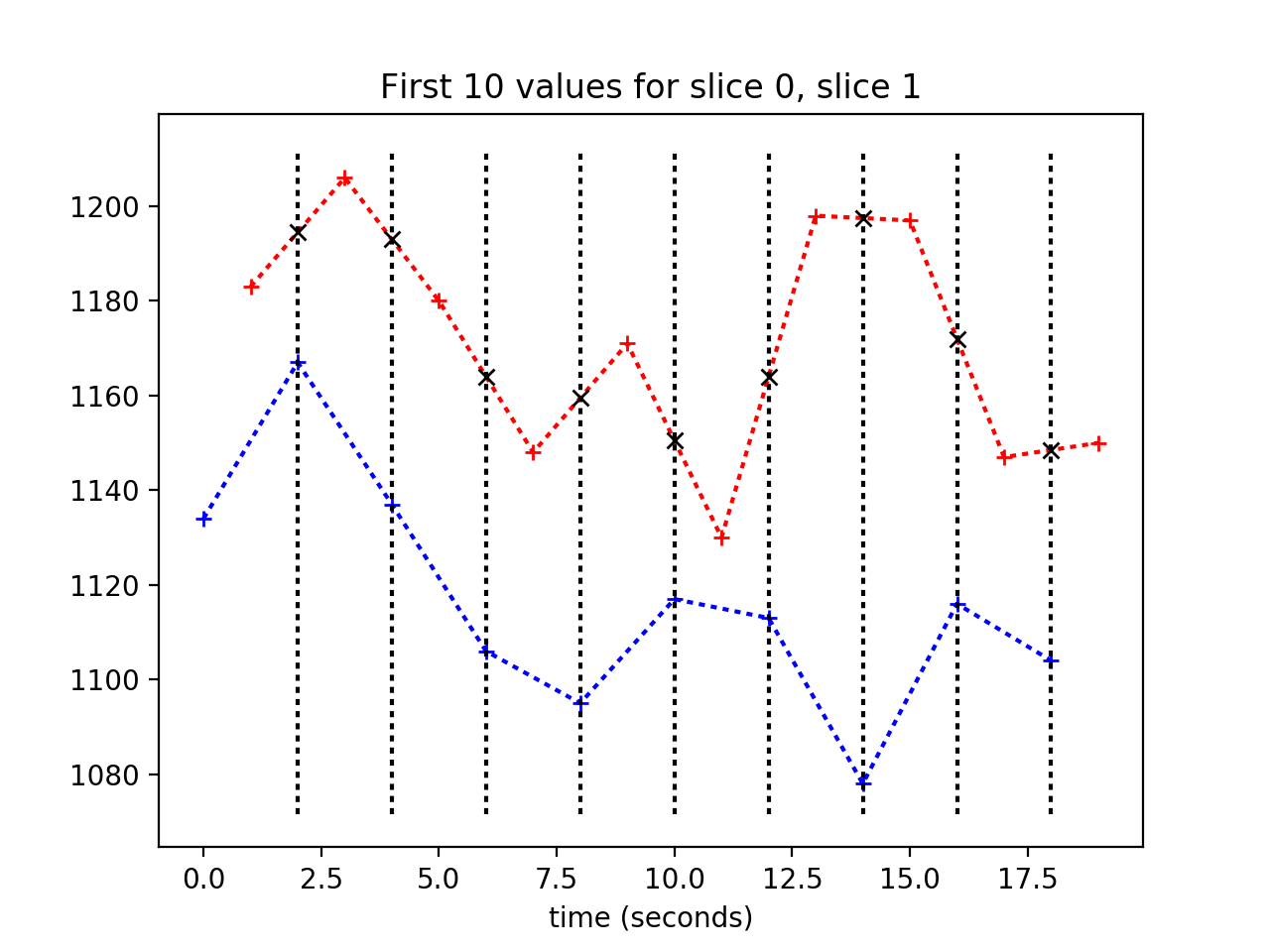
We want to work out a best guess for what the values in slice 1 would be, if we collected them at the beginning of the TR – at the same times as the values for slice 0.
One easy way to do this, might be to do the following for each of our desired samples at times \(t \in 0, 2, 4, ... 198\):
- draw a vertical line at \(x = t\);
- at the point where the line crosses the slice 1 time course, draw a horizontal line across to the y axis;
- take this new y value as our interpolation of the slice 1 course, at time \(t\).
Here are the vertical lines at the times of slice 0:
>>> plt.plot(times_slice_0[:10], time_course_slice_0[:10], 'b:+')
>>> plt.plot(times_slice_1[:10], time_course_slice_1[:10], 'r:+')
>>> plt.title('First 10 values for slice 0, slice 1')
>>> plt.xlabel('time (seconds)')
>>> min_y, max_y = plt.ylim()
>>> for i in range(1, 10):
... t = times_slice_0[i]
... plt.plot([t, t], [min_y, max_y], 'k:')
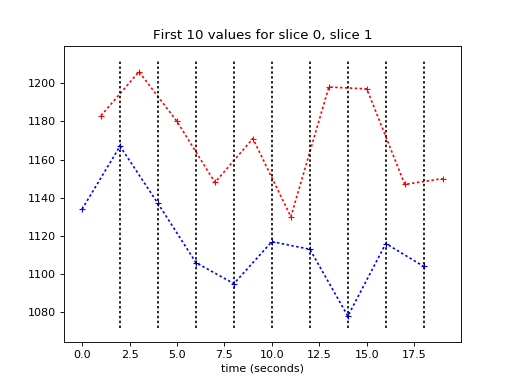{kind=link}
{kind=link}
Now we need to work out where these lines cross the slice 1 time course.
This is where we can use linear interpolation. This is interpolation because we are estimating a value from the slice 1 time course, that is between two points that we have values for (inter == between). It is linear interpolation because we are getting our estimate by assuming a straight line between to the two known points in order to estimate our new value.
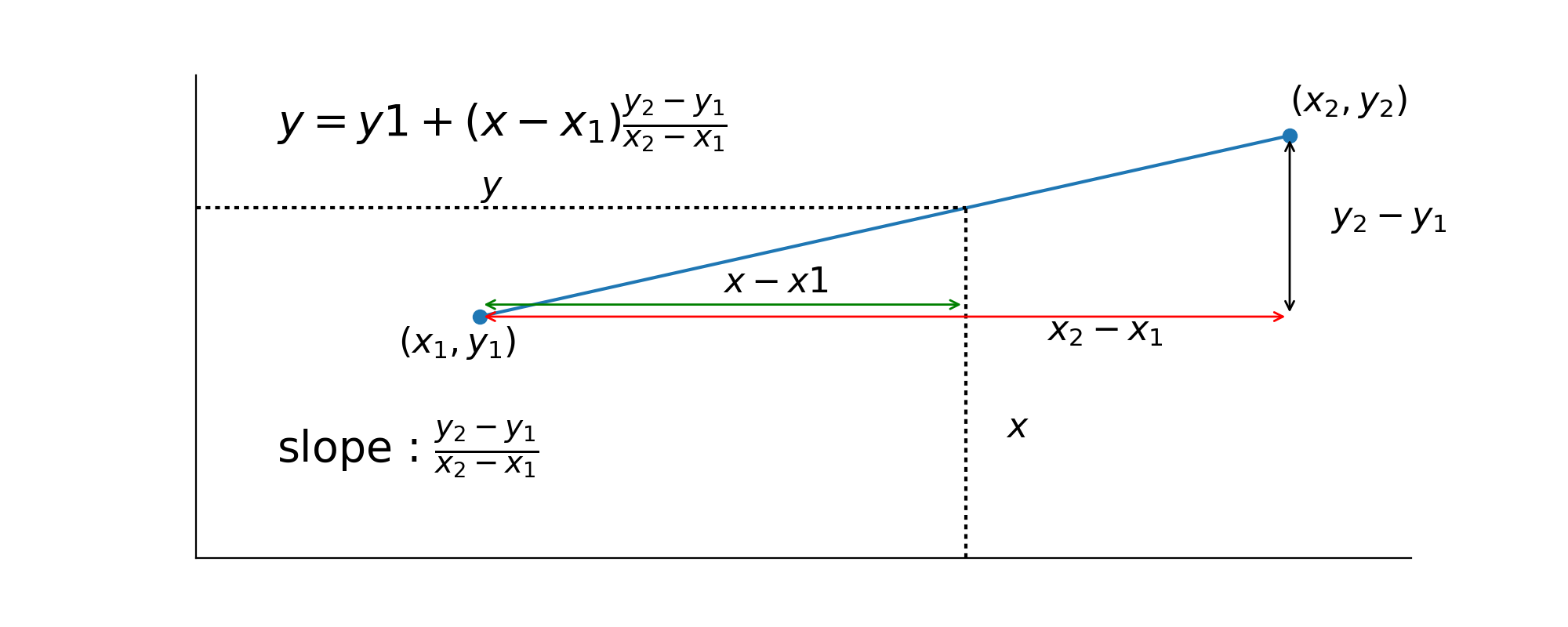
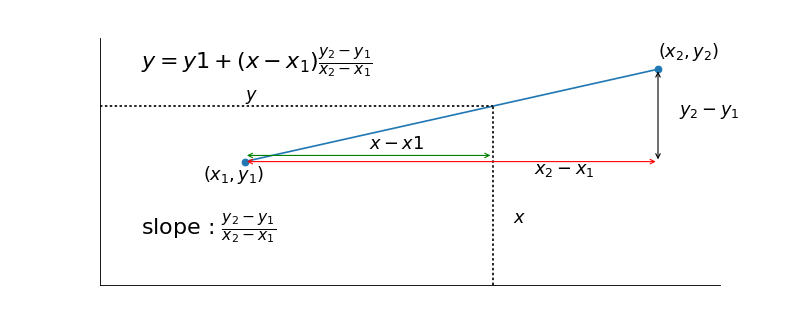
In general, linear interpolation works like this.
Let’s say we have two known points \(x_1, y_1\) and \(x_2, y_2\). We want to estimate a value for \(y\) given we have a value \(x\) that is between \(x_1\) and \(x_2\). It’s not hard to show that the formula of the line between \(x_1, y_1\) and \(x_2, y_2\) is \(y = y1 + (x-x_1)\frac{y_2-y_1}{x_2-x_1}\) (see wikipedia on linear interpolation).
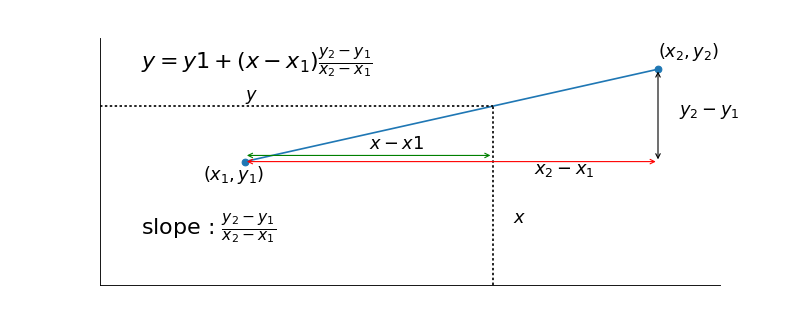{kind=link}
{kind=link}
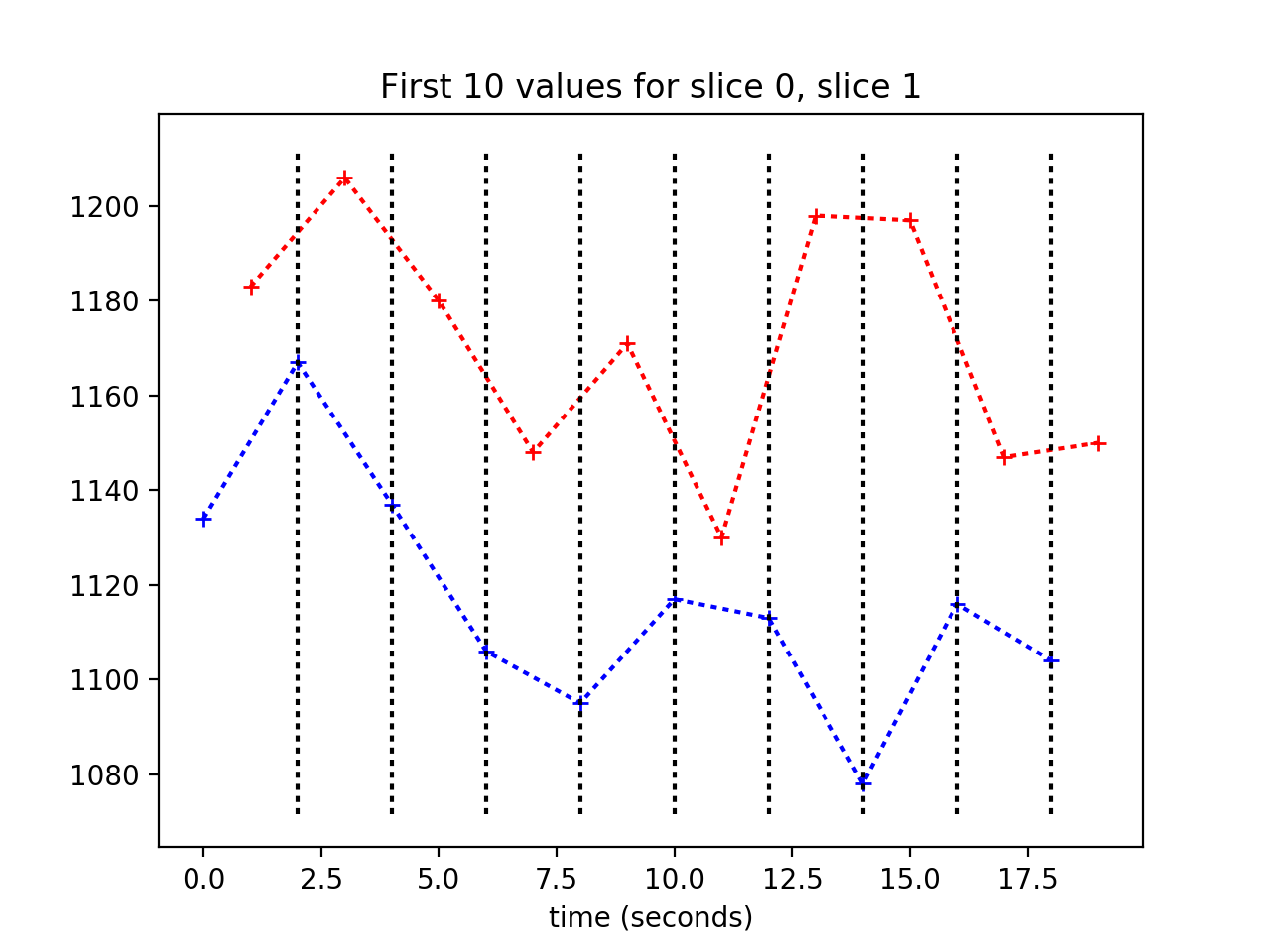
Now we know the formula for the interpolation, we can apply this to find the interpolated values from the slice 1 time course:
>>> plt.plot(times_slice_0[:10], time_course_slice_0[:10], 'b:+')
>>> plt.plot(times_slice_1[:10], time_course_slice_1[:10], 'r:+')
>>> plt.title('First 10 values for slice 0, slice 1')
>>> plt.xlabel('time (seconds)')
>>> min_y, max_y = plt.ylim()
>>> for i in range(1, 10):
... t = times_slice_0[i]
... plt.plot([t, t], [min_y, max_y], 'k:')
... x = t
... x0 = times_slice_1[i-1]
... x1 = times_slice_1[i]
... y0 = time_course_slice_1[i-1]
... y1 = time_course_slice_1[i]
... y = y0 + (x - x0) * (y1 - y0) / (x1 - x0)
... plt.plot(x, y, 'kx')
{kind=link}
{kind=link}
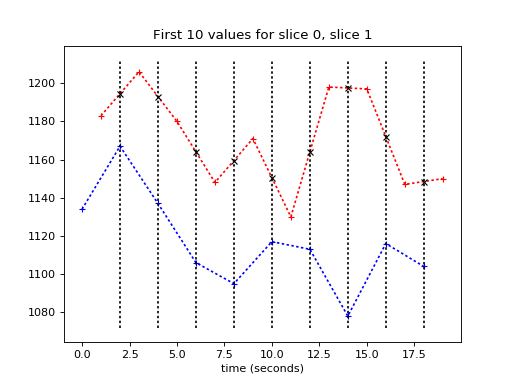
It is inconvenient to have to do this calculation for every point. We also need a good way of deciding what to do about values at the beginning and the end.
Luckily scipy has a sub-package called scipy.interpolate that takes
care of this for us.
We use it by first creating an interpolation object, that will do the interpolation:
>>> from scipy.interpolate import InterpolatedUnivariateSpline as Interp
This class can do more fancy interpolation, but we will use it for linear
interpolation (k=1 argument below):
>>> lin_interper = Interp(times_slice_1, time_course_slice_1, k=1)
>>> type(lin_interper)
...InterpolatedUnivariateSpline
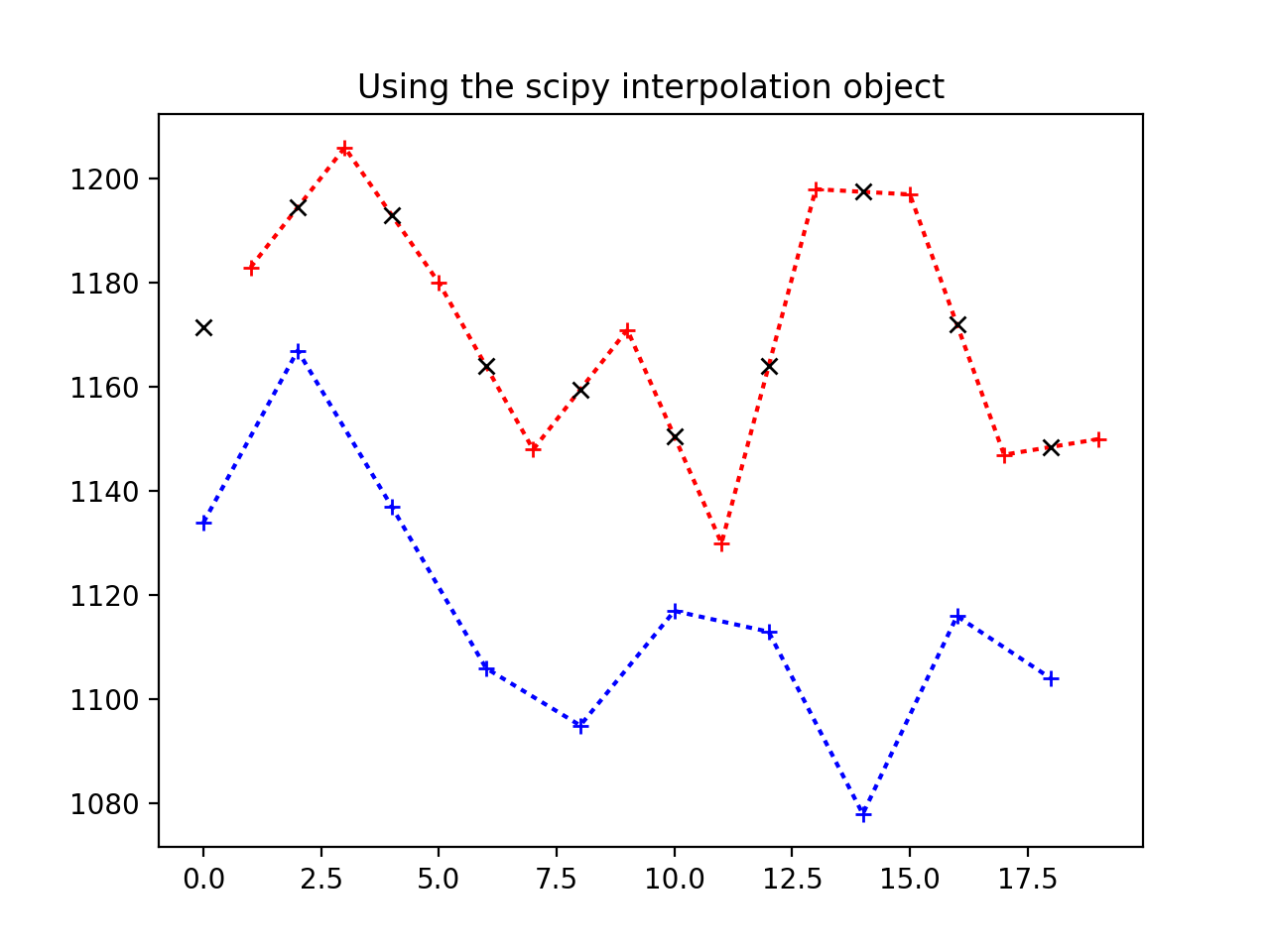
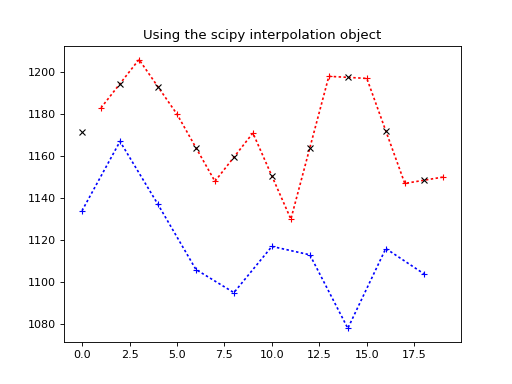
Our new object knows how to get the linear interpolation between the y values we passed in, given new x values. Here it is in action replicating our manual calculation above.
We use the interpolator to get the values for slice 0 times:
>>> interped_vals = lin_interper(times_slice_0)
>>> plt.plot(times_slice_0[:10], time_course_slice_0[:10], 'b:+')
>>> plt.plot(times_slice_1[:10], time_course_slice_1[:10], 'r:+')
>>> plt.plot(times_slice_0[:10], interped_vals[:10], 'kx')
>>> plt.title('Using the scipy interpolation object')
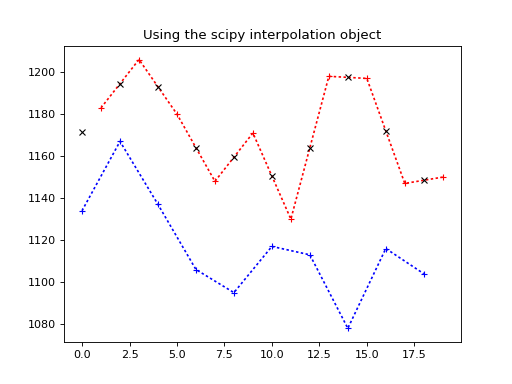{kind=link}
{kind=link}
So now we can just replace the original values from the red line (values for
slice 1) with our best guess values if the slice had been taken at the same
times as slice 0 (black x on the plot). This gives us a whole new time
series, that has been interpolated from the original:
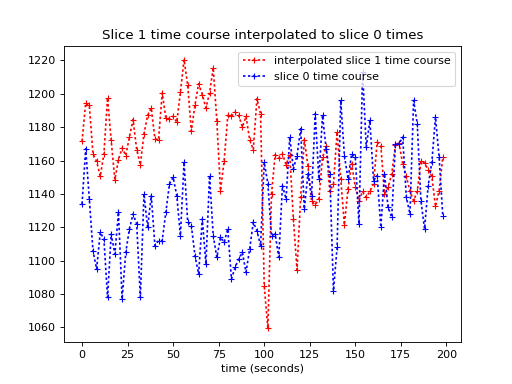
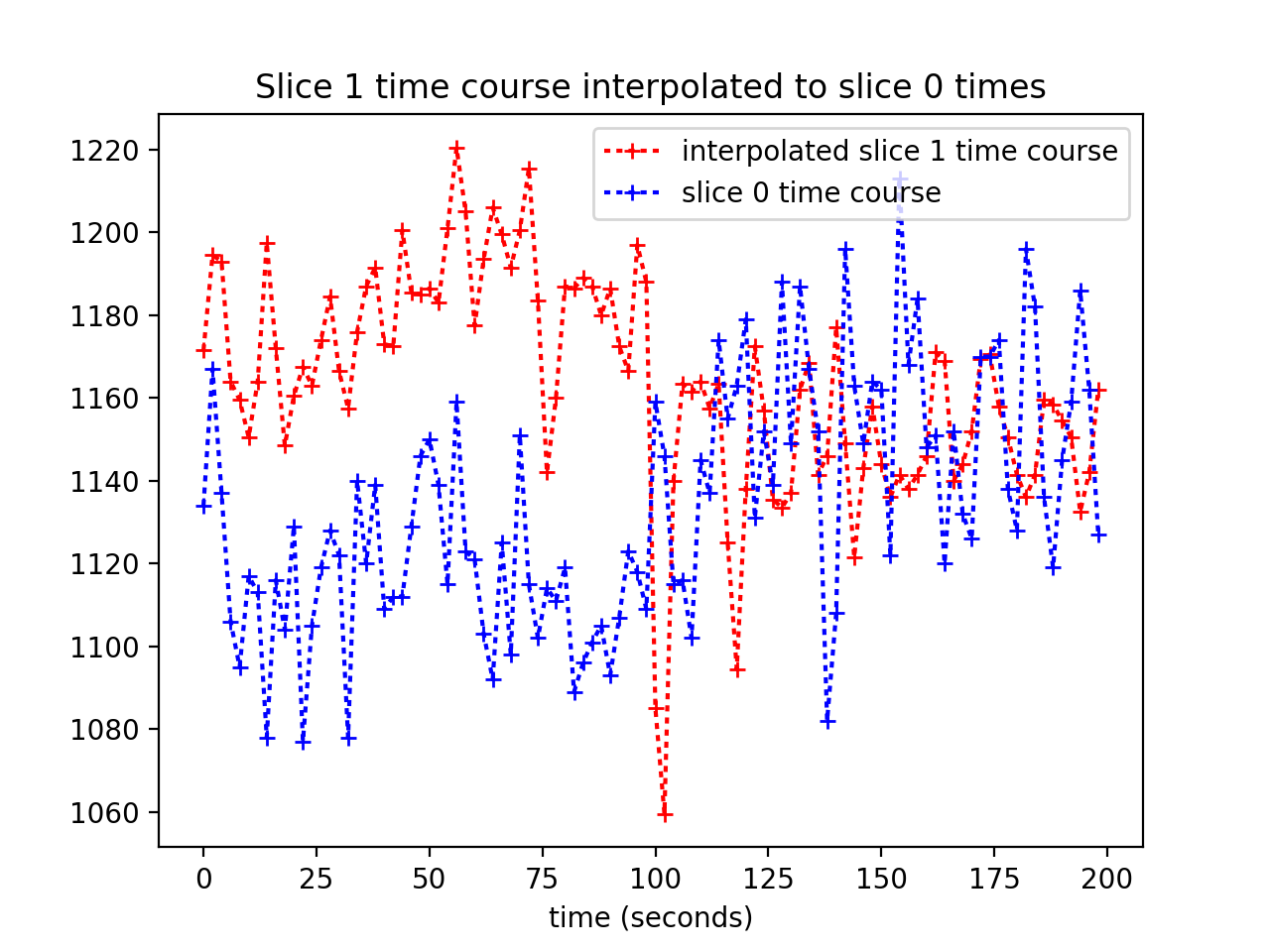
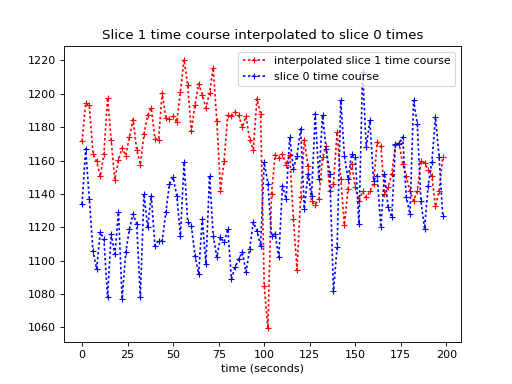
We plot the interpolated time course against the slice 0 times:
>>> plt.plot(times_slice_0, interped_vals, 'r:+',
... label='interpolated slice 1 time course')
>>> plt.plot(times_slice_0, time_course_slice_0, 'b:+',
... label='slice 0 time course')
>>> plt.legend()
>>> plt.title('Slice 1 time course interpolated to slice 0 times')
>>> plt.xlabel('time (seconds)')
{kind=link}
{kind=link}
Slice time correction¶
We can do this for each time course in each slice, and make a new 4D image, that has a copy of the values in slice 0, but the interpolated values for all the other slices. This new 4D image has been slice time corrected.